Das ist kein Grund für Zynismus, aber ein guter Grund für etwas mehr Präzision. Die folgenden drei Tipps sind kein Überblick über den Stand der Technik – dafür gibt es bessere Quellen. Es sind Denkwerkzeuge: Wege, mit denen man KI-Meldungen, KI-Versprechen und KI-Warnungen etwas nüchterner lesen kann, ohne sie komplett auszublenden.
1. “KI” ist Branding
Was ist eigentlich “KI”? Nimm dir einen Moment und versuche, eine präzise Definition zu finden, die der Breite des Begriffs gerecht wird. Schwierig, richtig?
Insbesondere dann, wenn man versucht, der Geschichte des Feldes gerecht zu werden. “KI ist das, was Computer noch nicht können,” war Jahrzehnte lang die etwas zynische Antwort auf ein Feld, das seine Grenzen immer wieder neu gezogen hat, je nachdem, welche Herangehensweisen am vielversprechendsten waren. Die Geschichte des Begriffs ist auch weitaus weniger linear, als gerne behauptet wird: “KI” wurde fünf Jahre nach Turings berühmtem Turing-Test erfunden und zu einem Zeitpunkt, an dem einige Wissenschaftler der Meinung waren, dass Computer längst denken würden.
Die beste Art, “KI” also zu verstehen, ist, den Begriff wie ein Marken-Branding zu lesen [1]. Der Grund, weshalb selten präziser über Sprachmodelle, statistische Lernverfahren oder Automatisierungssysteme gesprochen wird, ist, dass die Unschärfe des Begriffs “KI” ihn für alle Beteiligten so wertvoll macht: Es ist nicht notwendig zwischen Fiktion, Marketing und Realität zu unterscheiden.
Wenn du also in 2026 mit einer KI-Meldung konfrontiert wirst, lohnt es sich, kurz zu innezuhalten und zu fragen: Auf welcher Ebene spielt das eigentlich?
- Science-Fiction (Was wird impliziert oder befürchtet?)
- Marketing (Was wird verkauft oder finanziert?)
- Technische Realität (Was macht das System konkret? Nicht nur: Was wird mir darüber erzählt?)
2. Mythen brauchen keine Fakten
Wie versteht man nun aber Analysen über die Entwicklung von “KI”-Systemen? Wie etwa den gerne geteilten METR-Graph, der versucht zu messen, wie gut LLM-Systeme darin sind, komplexe Softwareprobleme zu lösen?
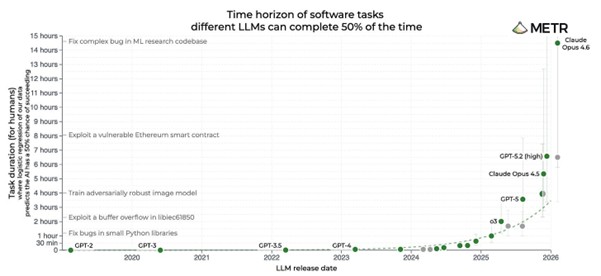
Der Graph erzählt eine einfache Geschichte: Die Modelle zeigen eine exponentielle Entwicklung ihrer Fähigkeiten.
Vorausgesetzt, man ignoriert die Fehlerbalken und die Tatsache, dass der Graph nur misst, ob die Systeme in 50% aller Versuche Erfolg hatten (die Geschichte sieht bei 80% schon deutlich nüchterner aus, aber dieser Graph ist im dazugehörigen Paper versteckt und überhaupt hat das Ganze mehr methodische Probleme als meine Bachelorarbeit.)
Und trotzdem hat dieser Graph Einfluss: Er bewegt Börsenkurse, sorgt dafür, dass sich gerade in diesem Moment vielleicht Schüler*innen für andere Studiengänge entscheiden oder Unternehmen andere strategische Richtungen einschlagen.
Das liegt daran, dass er als Mythos wirkt. Ein Mythos muss geglaubt und weitererzählt werden, um Wirkung zu haben – er muss nicht korrekt sein. [2] So können Geschichten über “KI” bereits einen Einfluss haben, nicht weil sie korrekt sind, sondern schlicht nur weil sie glaubwürdig wirken. Einen Mythos stellt man entsprechend auch nicht mit der Frage “Stimmt das?”, sondern mit “Wem nützt diese Geschichte und was bewirkt sie?” [3]
Zur Entzauberung der Mythen kann zum Beispiel dieser Blogartikel beim Civic Data Lab beitragen.
3. Was eine Technologie wirklich tut
Abgesehen von der Rolle des METR-Graphen als Mythos lässt sich eine Technologie nicht allein anhand ihrer Fähigkeiten verstehen. Besser ist es, die Affordances einer Technologie zu betrachten. [4]
Wir nehmen Objekte nicht als neutrale Dinge wahr, sondern als Handlungsangebote. Eine flache Fläche lädt zum Sitzen ein. Ein Griff fordert zum Greifen auf. Affordances existieren weder im Objekt allein noch im Betrachter, sondern in der Beziehung zwischen beiden.
Das bedeutet: Eine Treppenstufe hat für ein Kind andere Affordances als für einen Rollstuhlfahrer. Nicht weil die Stufe sich verändert, sondern weil sich der*die Akteur*in, sein Kontext und seine Fähigkeiten verändern.
Statt also zu fragen “Was kann dieses System?“, könnte man fragen:
- Welche Handlungen legt dieses System für wen nahe und welche nicht?
- Welche Affordances existieren nur auf dem Papier, weil die realen Nutzer*innen, Kontexte oder Voraussetzungen fehlen? [5]
- Wer nutzt das tatsächlich und wofür? Laborergebnisse und Realeinsatz sind zwei sehr unterschiedliche Dinge. [6]
- Was ändert sich konkret im Vergleich zu vorher? Was tun Menschen jetzt anders als zuvor und was nicht? [7]
“KI” verstehen heißt letztendlich also nicht, jede technische Entwicklung im Detail zu verfolgen. Es heißt, mehrere Aspekte auseinanderhalten zu können: Was wird behauptet? Was wird verkauft? Was passiert tatsächlich – für wen und unter welchen Bedingungen?
Wer sich für KI-Kompetenzen tiefergehend interessiert, findet hier den passenden Online-Kurs des Civic Data Lab.
Quellen:
- [1] Etwas akademischer: “KI” kann auch als floating signifier verstanden werden, als “a term that suggests a specific referent but works to escape definition in order to maximize its suggestive power” (Suchman, 2023).
- [2] Natale & Ballatore (2017) nutzen den Mythos-Begriff sehr explizit, in ihrer Analyse von “KI”-Storytelling, und van Lente (2012) nutzt eine ähnlich konstruktivistische Perspektive auf die Macht von Erwartungen bei der Entwicklung neuer Technologien.
- [3] Trotz aller gegenteiligen Vorhersagen der letzten Jahre sind beispielsweise Produktivitätssteigerungen auf Unternehmensebene bisher kaum vorhanden, der Beitrag von “KI” zum GDP-Wachstum der USA war mehr oder weniger null und die Nachfrage nach Software-Entwickler:innen wächst tatsächlich, wenn auch langsam und vor allem langsamer als die Abschlussrate von Studierenden.
- [4] Die deutsche Übersetzung wäre hier “Affordanzen” – was zugegebenerweise mehr nach einem Organ des Öffentlich-Rechtlichen Rundfunks klingt. Entwickelt wurde der Begriff vom Psychologen James Gibson (1979). Hutchby (2001) bietet einen guten Überblick über Affordances im Kontext von Technologien.
- [5] Das ist auch einer der Gründe, weshalb von Early-Adopter-Nutzung fast nie auf die Nutzung in der breiten Masse geschlossen werden kann. Early Adopter verfügen über Zeit, Ressourcen und Zugang, die die Masse nicht hat. Letztere treffen Entscheidungen in der Regel mit begrenzten Ressourcen und knapper Zeit und oft für Technologien, die “gut genug” sind.
- [6] Beane (2020) hat gezeigt, dass, obwohl medizinische Roboter oft in der Praxis kaum genutzt wurden, ihr tatsächlicher Wert—ihre Affordance—darin lag, Stakeholder davon zu überzeugen, dass das jeweilige Krankenhaus fortschrittlich ist. Siehe das Thema Branding.
- [7] Ricci & Alcaras (2025) haben in dem Kontext das, meiner Meinung nach, umfassendste Framework dafür entwickelt, was es bedeutet, LLMs tatsächlich in die eigene Arbeit zu integrieren. Sie sprechen hier auch von einer Rekonfiguration, nicht von Automatisierung oder Augmentierung.
